
Capire Adam : come le funzioni di perdita sono minimizzate ?
- Literature & Cie

- 24 janv. 2021
- 4 min de lecture
Introduzione
Mentre utilizzavo la libreria fast.ai costruita sopra PyTorch, mi sono reso conto che finora non ho mai dovuto interagire con un ottimizzatore. Poiché fast.ai si occupa già di esso quando si chiama il metodo fit_one_cycle, non devo parametrizzare l'ottimizzatore né capisco come funziona.
Adam è probabilmente l'ottimizzatore più utilizzato nel machine learning grazie alla sua semplicità e velocità. È stato sviluppato nel 2015 da Diederik Kingma e Jimmy Lei Ba e introdotto in un articolo intitolato Adam : un metodo per l'ottimizzazione stocastica.
Come sempre, questo post sul blog è un foglio trucco che scrivo per verificare la mia comprensione di una nozione. Se trovi qualcosa di poco chiaro o scorretto, non esitare a scriverlo nella sezione commenti.

Algoritmo
Prima di tutto, Adam significa Stima del Momento Adattabile. La logica alla base di Adam è di trovare un algoritmo efficiente per ottimizzare una funzione oggettiva. Il documento di ricerca si concentra sull'ottimizzazione degli obiettivi stocastici in spazi di parametri ad alta dimensione.
Adam è una versione modificata di Stochastic Gradient Descent, che non spiegherò qui. Per memoria, la regola di aggiornamento di Stochastic Gradient Descent è :

Lo pseudo-codice dell'algoritmo di Adam è il seguente :

Spiegherò chiaramente ogni passo, ma prima devo introdurre alcune quantità.
Poiché Adam è un processo iterativo, abbiamo bisogno di un indice t che è incrementato di 1 ad ogni passo.
α è la stepsize, un equivalente del tasso di apprendimento per la discesa a gradiente stocastico.
G(t) è il gradiente della funzione obiettivo f al passaggio t rispetto al vettore del parametro θ.
M(t) è la media mobile esponenziale (EMA) del primo momento del gradiente G(t). Quindi β1 è il tasso di decadimento esponenziale per l'EMA.
V(t) è la media mobile esponenziale del secondo momento del gradiente G(t). Quindi β2 è il tasso di decadimento esponenziale per l'EMA.
Infine, ε è un iperparametro molto piccolo che impedisce all'algoritmo di dividersi per zero.
Perché Adam usa il gradiente EMA e non il gradiente ?
Quando il gradiente viene calcolato, alcuni mini-batch possono avere outlier che possono produrre grandi gradienti informativi, quindi calcolando l'EMA dei gradienti per ogni mini-batch, l'effetto dei gradienti non formativi è minimizzato. Inoltre, l'EMA è una media ponderata dei gradienti nuovi e vecchi. Se Adam avesse usato una media aritmetica, tutti i gradienti (tra 1 e t-esimo passo) avrebbero avuto lo stesso peso.
Notiamo che l'EMA agisce come una stima del gradiente come vedremo più avanti.
Regola di aggiornamento di Adam
Come detto sopra, la regola di aggiornamento di Adam non è altro che una versione modificata della regola di aggiornamento di discesa di Gradient. In Adam, l'EMA del primo momento del gradiente scalato dalla radice quadrata del secondo momento del momento è dedotto dal vettore del parametro θ.
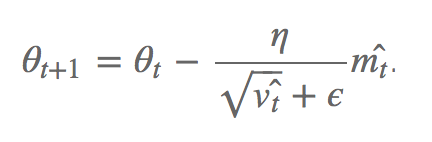
Nel documento, gli autori definiscono questo come il SNR (il rapporto segnale-rumore).
Il SNR è una misura che confronta il livello di un segnale desiderato (qui il gradiente i.e. la direzione della curva di funzione dell'obiettivo) con il livello di rumore di fondo (il gradiente di secondo ordine i.e. il rumore intorno a questa direzione).
La scala quadrata-radice è presa dall'algoritmo Rmsprop (RMS significa Root Mean Square). L'idea è che poiché i gradienti sono accumulati su più mini-lotti, abbiamo bisogno che il gradiente ad ogni passo rimanga stabile. Poiché un mini-lotto può avere un campione di dati radicalmente diverso da un altro mini-lotto, per limitare la variazione del gradiente l'EMA del primo momento del gradiente viene scalato dal RMS del secondo momento. Si potrebbe pensare a questa tecnica come una sorta di normalizzazione in cui il gradiente è diviso da una sorta di deviazione standard.
Ricottura automatica
Con un SNR più piccolo, il passo effettivo sarà più vicino a zero, il che significa che esiste un sacco di rumore rispetto al segnale reale, quindi una maggiore incertezza circa se la direzione del gradiente del primo ordine corrisponde alla direzione dell'ottimale. Questa è una proprietà desiderabile in quanto i passaggi sono più piccoli, limitando quindi la divergenza da un ottimale locale.
Il SNR tipicamente diventa più vicino a 0 verso un ottimale, portando a piccoli passi efficaci nello spazio dei parametri. Questo permette una convergenza più robusta e più veloce verso l’ottimale.
Correzione bias di inizializzazione
Poiché i vettori EMA sono inizializzati come vettori di 0, le stime dei momenti sono orientate verso lo zero, specialmente durante i primi passi temporali, e soprattutto quando i tassi di decadimento sono piccoli (i βs sono vicini a 1).
Per controbilanciare questo, le stime di momento sono bias-corrette.
Usando la relazione ricorrente tra v(t) e v(t-1), segue che :

Dopo aver usato questa equazione componendola con l'aspettativa, segue rapidamente che, E[v(t)] è uguale

Ecco perché per inizializzare i pesi ad ogni passo, E[v(t)] è diviso per (1-β2 t).
Lo stesso ragionamento segue per il primo momento di gradiente.
Adamax : estensione di Adam
Adamax è un'estensione di Adam. Sostituisce il secondo momento del gradiente con una norma di infinito ponderata.

Questa variante è usata poiché gli autori hanno trovato una soluzione sorprendentemente stabile quando la matrice delle caratteristiche è sparsa (come negli embedding, pensate alla codifica a caldo). In effetti, la soluzione è robusta poiché la regola di aggiornamento per u(t) non si basa esclusivamente sul gradiente.

Quando g(t) diventa veramente piccolo, la regola di aggiornamento sceglie β2*u(t-1) grazie alla funzione max.
Risultati

Figura 2 : Formazione di reti neurali multistrato su immagini MNIST. (a) Reti neurali con regolarizzazione stocastica a caduta. (b) Reti neurali con funzione di costo deterministico. Confrontiamo con l'ottimizzatore della somma delle funzioni (SFO) (Sohl-Dickstein et al., 2014)
Confrontando i risultati sul set di dati MNIST, osserviamo che Adam converge molto più velocemente e più vicino all'ottimale di Adagrad, Rmsprop o Adadelta.
Fonte (articolo di origine) : https://towardsdatascience.com/understanding-adam-how-loss-functions-are-minimized-3a75d36ebdfc
Tutti i suoi articoli : https://medium.com/@PABTennnis
Chi ha Twitter, segui @el_PA_B, link a fianco : https://twitter.com/el_pa_b

Commentaires