
Comment créer un réseau neuronal à partir de zéro dans Python — Math & Code
- Literature & Cie

- 5 févr. 2021
- 9 min de lecture
Dans cet article, j’essaie de vous expliquer de manière complète et mathématique comment fonctionne un simple réseau neuronal à 2 niveaux, en codant un à partir de zéro en Python.
Cet article est écrit autant pour vous aider à comprendre les coulisses d’un tel algorithme populaire, que pour moi d’avoir un aide-mémoire qui explique dans mes propres mots comment un réseau neuronal fonctionne.
Tout d’abord, nous étudions la logique derrière l’élaboration de ces algorithmes et l’intuition mathématique qui les sous-tend. Ensuite, nous plongeons dans le codage d’un réseau neuronal (mélange de lignes de code Python et d’équations mathématiques). Finalement, nous imaginons comment nous pourrions généraliser notre modèle et le rendre plus adaptable pour résoudre des problèmes complexes de la vie réelle.
Pourquoi avons-nous besoin de réseaux neuronaux ?
L’apprentissage automatique peut être défini comme toutes les techniques utilisées pour former un ordinateur à accomplir une tâche sans être explicitement codé pour le faire. Bien que cette définition puisse sembler ésotérique, elle peut être facilement comprise.
Disons que nous avons une équation simple :

Dans cette équation, x est une variable donnée et y est une variable dépendante de x. f est une fonction inconnue. Par exemple, dans une voiture autonome x pourrait être l’environnement entourant une voiture (les autres voitures, les panneaux de circulation, la couleur des feux de circulation…) et y comment la voiture se comporte par rapport à ces éléments. Dans l’apprentissage automatique, comme on ne sait pas f, on utilise des méthodes statistiques pour s’en approcher le plus possible.
f peut avoir beaucoup de formes. Le plus simple est quand f est linéaire. Dans ce cas, f ressemble à :

Où a et b sont des nombres réels que nous approchons grâce à des méthodes statistiques. En particulier, nous utilisons la fameuse méthode de régression linéaire pour déterminer les deux coefficients a et b.
Mais si f n’est pas linéaire ?
Comment pouvons-nous savoir quelle forme elle a ? Est-elle exponentielle ? Quadratique ? Pour la plupart des fonctions, en fait nous ne pouvons pas savoir.
Ici, l’astuce vient d’un théorème démontré par Kurt Hornik appelé le théorème d’approximation universelle :

Pour nous, les maths profanes, cela dit simplement qu’en additionnant suffisamment de fonctions linéaires et en les transformant avec la même fonction non-linéaire, on peut approcher n’importe quelle fonction f.
Autrement dit, en sélectionnant les bons poids et les bons biais, nous pouvons estimer n’importe quelle fonction non linéaire. Et c’est un gros problème puisque dans notre monde beaucoup de relations entre un intrant et un extrant sont non linéaires.
Construire un réseau neuronal à partir de zéro
Maintenant que nous avons une idée de ce à quoi sert un réseau neuronal, essayons d’en coder un. Pour plus de clarté, nous décomposons le fonctionnement d’un réseau neuronal en plusieurs étapes :
La structure
Propagation d’alimentation
La fonction de perte
La rétro-propagation de gradient et les équations mathématiques sous-jacentes
Faire fonctionner notre réseau neuronal
La structure
Dans cet article, nous allons seulement créer un réseau neuronal à deux niveaux, mais l’idée reste la même pour les réseaux neuronaux à plus de deux niveaux.
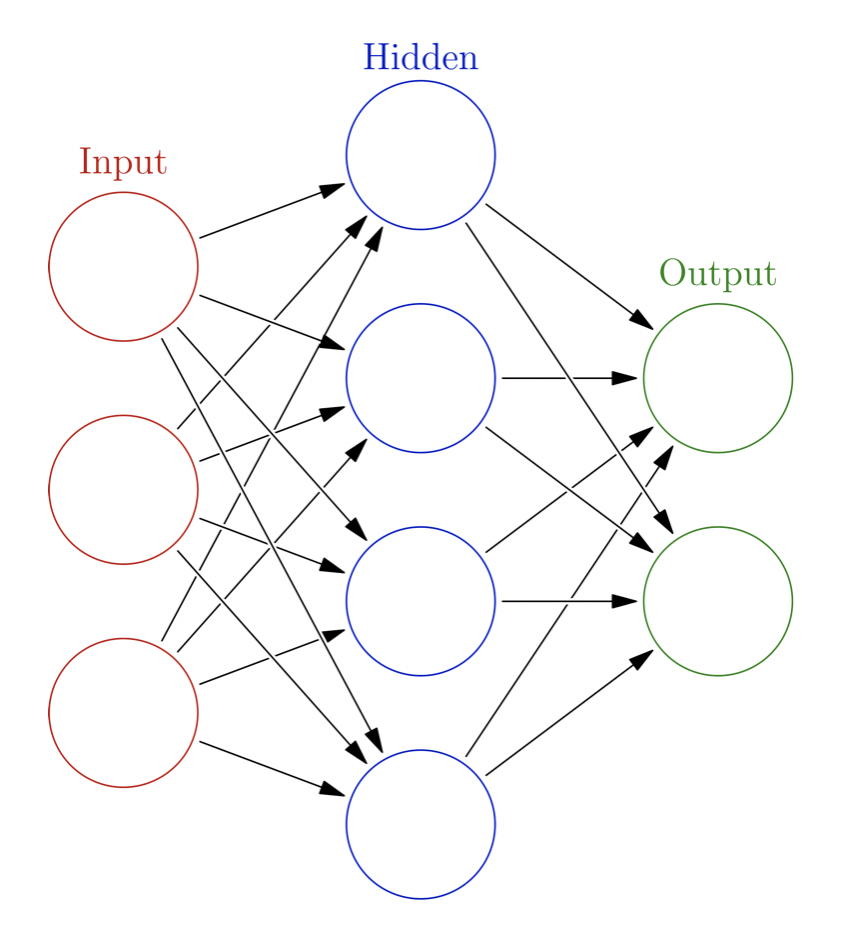
Comme vous pouvez le voir sur l’image, notre réseau neuronal est composé de trois couches : une couche d’entrée, une couche cachée et une couche de sortie.
NB : Nous omettons habituellement la couche d’entrée, d’où le nom de « réseau neuronal à deux couches ».
Les connexions faites entre les calques d’entrée et les calques cachés ainsi qu’entre les calques cachés et les calques de sortie sont appelées poids.
Pour calculer les valeurs dans les cellules (nous les appelons activations), nous utilisons une équation mathématique que nous connaissons bien :

Où a est l’activation, x l’entrée, W les poids, b les biais et φ une fonction non-linéaire appelée la fonction d’activation (vous pouvez également entendre la non-linéarité).
La fonction d’activation crée la non-linéarité dans notre modèle. Vous devriez rappeler le théorème universel ici. En effet, nous trouvons la même structure. Donc, pour créer la structure de notre réseau neuronal, nous avons besoin de :
Une entrée x (les cellules rouges dans l’image ci-dessus)
Une sortie cible y
Une couche de sortie (les cellules vertes dans l’image ci-dessus)
Vecteurs de pondération
Vecteurs de biais
Dans l’extrait de code suivant, nous définissons la fonction __init__ de notre classe NeuralNetwork.

Vous pouvez également observer un taux d’apprentissage. Je suppose que la familiarité avec les concepts de base de l’apprentissage automatique. Si vous ne savez pas quel est le taux d’apprentissage, je vous recommande le fameux cours de Machine Learning Andrew Ng de l’Université de Stanford que vous pouvez trouver sur Coursera.
Comme vous pouvez le voir, j’initialise mes poids aléatoirement avec de petits nombres puisque nous allons implémenter un algorithme de descente de gradient en quelques minutes pour optimiser nos poids et biais. Nous ne pouvons pas définir nos poids à zéro, puisque le modèle ne mettrait pas à jour les équations de descente de gradient. Si vous voulez en savoir plus, lisez https://machinelearningmastery.com/why-initialize-a-neural-network-with-random-weights/
De plus, nous créons un vecteur poids1 qui a une forme (nombre de lignes de notre couche d’entrée, nombre de lignes du calque caché). De même, le vecteur poids2 a une forme (nombre de lignes du calque caché, nombre de lignes du calque de sortie). Vous pouvez le voir clairement sur l’image ci-dessus où les matrices de poids font les connexions entre les calques.
La propagation d’alimentation
Pour former un réseau neuronal, il y a trois étapes de base.
Premièrement, vous calculez toutes vos activations. Deuxièmement, vous calculez votre erreur. Troisièmement, vous optimisez les poids pour minimiser l’erreur de votre modèle. Vous faites ces trois étapes de façon itérative quelques centaines de fois (nous les appelons époques), afin de construire un modèle suffisamment précis.

La propagation feedforward vise à calculer les activations. N’oubliez pas que nous calculons d’abord l’équation vectorisée z = x*W+b, puis nous appliquons la fonction d’activation φ.
La fonction d’activation que nous avons choisie est la fonction sigmoïde. Il a des propriétés remarquables, dont l’une est particulièrement utile, ses dérivés donnent l’équation :

Comme vous le verrez, cette propriété nous aidera grandement à simplifier nos calculs. Une autre propriété intéressante est que les poids sont des nombres réels entre 0 et 1. Ainsi, nous avons des nombres assez petits dans notre réseau neuronal, et nous ne risquons pas d’avoir un réseau neuronal lent en raison de calculs lourds.
NB : De nos jours, presque tous les réseaux utilisent la fonction ReLU (Rectified Linear Unit) comme fonction d’activation principale, sauf pour la dernière couche.
Nos activations sont calculées comme suit : a = sigmoid(z).

D’où le code :

La fonction de perte
Maintenant que nous avons défini le processus de base de notre algorithme, nous avons besoin de quelque chose pour calculer notre erreur sur le réseau. Rappelez-vous, un réseau neuronal est un processus en trois étapes. D’abord, nous calculons une sortie, ensuite une erreur et enfin nous minimisons l’erreur. Afin de calculer l’erreur, nous utilisons une fonction de perte. Il existe beaucoup de fonctions de perte, ici nous prenons la fonction de perte d’entropie croisée, qui est :

Si vous voulez en savoir plus sur l’origine de cette fonction et en avoir une intuition, allez vérifier l’entropie de Shannon : https://en.wiktionary.org/wiki/Shannon_entropy
Pour calculer la perte à chaque étape de notre processus de rétro-propagation, nous appellerons cette fonction.

NB : Pour les problèmes de régression (c’est-à-dire les problèmes où des valeurs continues sont prévues), la fonction de perte d’erreur quadratique moyenne est souvent utilisée. Nous préférons la fonction d’entropie croisée puisque nous avons affaire à un problème de classification. La fonction d’entropie croisée pénalise fortement les prédictions discrètes erronées avec une confiance élevée, ce qui en fait un bien meilleur ajustement pour les problèmes de classification que la fonction d’erreur quadratique moyenne.

Le processus de rétro-propagation et les équations mathématiques sous-jacentes
Maintenant, voici la partie mathématique. En termes simples, l’idée de notre réseau neuronal est de minimiser la fonction de perte en trouvant les poids et les biais optimaux. Pour ce faire, nous utilisons un algorithme d’optimisation appelé l’algorithme de descente de gradient.
Avec une fonction J, une matrice de poids W et un taux d’apprentissage α, nous pouvons minimiser notre fonction en calculant itérativement :

Plus précisément, ∂J/∂W est le gradient de la fonction de perte.
Mais avant de plonger dans les maths, prenons une intuition sur la règle de la chaîne. Intuitivement, ce que nous essayons de calculer est combien w1 et w2 affectent notre fonction de perte, c’est l’erreur de notre réseau. Néanmoins, comme vous pouvez le voir dans l’expression de la fonction de perte, il n’y a pas de relation directe entre notre fonction de perte J et nos poids. J est défini par rapport à une cible et à une sortie. Par conséquent, nous devons « enchaîner » tous nos résultats pour dériver la variation de J induite par une variation de w1. En effet, nous dériverons d’abord la variation de notre production induite par une variation des poids, puis nous dériverons la variation de notre fonction de perte induite par une variation de notre production. Et en enchaînant tout ensemble, on peut trouver la variation de J induite par une variation de w1.
Les équations mathématiques suivantes montrent comment dériver le gradient à l’aide de la règle de chaîne.
Le premier consiste à dériver le gradient de l’erreur par rapport à chaque poids reliant la couche cachée à la couche de sortie.
Ces pondérations sont les coefficients dans notre matrice poids2 que nous avons créés précédemment.

où z2 est le point produit des activations cachées a1 et les poids reliant la couche cachée à la couche de sortie z2 = a1 * w2 + b2.
Ensuite, nous pouvons examiner chaque facteur. Premièrement :

Nous avons dérivé la fonction d’entropie croisée par rapport à la sortie.
Deuxièmement :

Rappelons que output = sigmoid(z2). De plus, n’oubliez pas la propriété spécifique des dérivés de la fonction sigmoid que j’ai expliquée plus haut.
Troisièmement :

depuis z2 = a1 * w2 + b2
En combinant les 3 équations ci-dessus, on obtient finalement :

Pour la deuxième étape, nous devons calculer le gradient de l’erreur par rapport à chaque poids reliant la couche d’entrée à la couche cachée (ou si nous avons un plus grand réseau neuronal, les couches cachées entre elles). Cette fois, les poids sont les coefficients de la matrice de pondération1 que nous avons créée précédemment dans la méthode __init__ de notre classe NeuralNetwork.
Pour ce faire, nous utilisons les calculs que nous avons faits auparavant. Comme vous pouvez le voir clairement, nous enchaînons le résultat puisque nous combinons chaque calcul que nous avons fait pour finalement arriver au poids1. Dans un réseau neuronal plus grand, nous ferions strictement la même chose, avec plus de matrices de poids à calculer.
De même, nous prenons z1 = w1 * x + b1 la somme d’entrée pondérée de notre réseau neuronal et a1 = sigmoid(z1) les activations de la couche cachée.
Nous commençons par dire que :

Nous y revoilà, étudions en profondeur les dérivés qui composent ∂J/∂W1.

Nous obtenons ce qui précède en suivant les calculs que nous avons faits précédemment.

depuis z2 = a1 * w2 + b2.

Encore une fois, rappelez-vous les dérivés d’une fonction sigmoïde.

depuis z1 = w1 *x + b1.
Ainsi, en combinant tout, on obtient :

Enfin, nous devons mettre à jour les biais de notre réseau neuronal. L’idée de base reste la même, nous devons calculer le gradient de la fonction de perte par rapport à b2 et b1 et mettre à jour nos biais. Nous y revoilà, mais cette fois les calculs sont beaucoup plus simples. Prenons un vecteur bi qui représente le biais pour la couche i, nous utilisons à nouveau la règle de la chaîne.
Maintenant, nous avons :

Mais :

puisque z(i) = a(i-1) * w(i) + b(i)
On obtient donc :

Ainsi, le code final :

Comme vous pouvez le voir, j’ai également inclus dans le code le taux d’apprentissage, selon l’algorithme de descente de gradient. Nous devons ensuite mettre à jour nos poids existants.
Faire fonctionner notre réseau neuronal
Maintenant que nous avons un réseau neuronal entièrement fonctionnel avec les processus feedforward et back-propagation mis en œuvre, nous pouvons créer une instance de notre classe de réseau neuronal et la laisser mettre à jour ses poids et ses biais pour un nombre prédéfini de fois (les époques).
Ici, 1500 fois pourrait être un bon début pour avoir un réseau neuronal assez performant.

Nous alimentons notre réseau neuronal avec un ensemble de formation, ici nous pouvons passer un tableau qui nous donne des données booléennes sur le facteur clé qui conduit une personne à avoir un diabète. Nous faisons notre réseau neuronal apprendre les modèles qui prédisent si une personne a ou non un diabète.
Retrouvez ci-dessous le code complet et en bonus, une fonction pour tracer l’évolution des coûts par rapport au nombre d’époques :



Si nous traçons l’évolution de notre perte, nous obtenons une forme courbe, ce qui est ce que nous voulons. Cela signifie que le réseau neuronal apprend correctement, n’étant pas coincé dans les optima locaux mais atteignant progressivement le minimum global.

Comme vous pouvez le voir, notre fonction de perte est minimisée lorsque l’algorithme atteint la 800ème époque. Ainsi, nous pouvons réduire notre nombre d’époques, pour optimiser notre réseau neuronal.
Et que faire ensuite ?
Maintenant que vous avez une compréhension claire du fonctionnement d’un réseau neuronal, vous pouvez généraliser le réseau neuronal en changeant le nombre de neurones pour chaque couche et même ajouter d’autres couches cachées.
Vous pouvez également mettre en œuvre des taux d’apprentissage cycliques car c’est un moyen facile d’atteindre des modèles d’apprentissage automatique de pointe, comme indiqué dans le cours fast.ai que je recommande fortement.
J’espère que vous avez apprécié cet article ; vous pouvez trouver ci-dessous toutes les références étonnantes que j’ai utilisées.
Tous les crédits leur sont attribués. Si vous avez des questions ou des remarques, n’hésitez pas à les commenter ci-dessous. Je suis loin d’être un expert en apprentissage automatique et toutes les corrections ou conseils sont les bienvenus !
Sources et références
Source (article d’origine)

Commentaires