
Coup d’œil sur la science des données concurrentielles :
- Literature & Cie

- 21 févr. 2021
- 10 min de lecture
Les meilleures pratiques en matière de vision par ordinateur
Comment plusieurs techniques peuvent améliorer considérablement le rendement de vos modèles de vision par ordinateur…
Introduction
Depuis la clôture du concours Freesound Audio Tagging 2019, j’ai décidé d’écrire un article sur les meilleures pratiques et techniques pour construire un modèle de vision par ordinateur robuste, que j’ai appris lors de mon premier concours de recherche. En outre, c’est une façon pour moi de mettre mes idées sur papier afin d’avoir un aperçu structuré et clair des techniques que j’ai utilisées : celles qui ont bien fonctionné, ainsi que celles qui n’ont pas donné une amélioration significative dans ma note de test.
En tant qu’étudiant du cours Fast.ai, je suis encore au tout début de mon parcours d’apprentissage, d’où quelques remarques ou techniques qui pourraient sembler évidentes pour les plus expérimentés d’entre vous.
Comme toujours, je vous encourage fortement à me corriger, à me demander des précisions sur un point précis si vous ne l’obtenez pas ou s’il n’est pas clair, et à ajouter quelques remarques dans la section des commentaires !
La leçon la plus critique que je tire de cette compétition est que la construction de modèles robustes est un processus empirique. La compétition aide à développer une intuition pour ce qui pourrait fonctionner ou non.
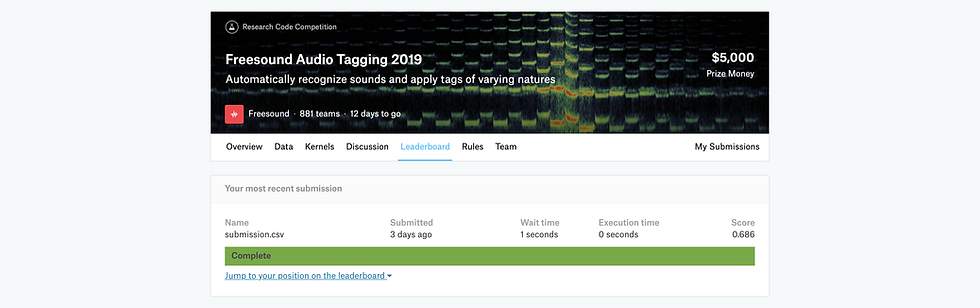
Pour vous donner un peu de contexte, le concours porte sur le marquage (classification) des sons (chat, chutes d’eau, instruments de musique…). On nous a donné deux jeux de données : un organisé avec des sons clairement audibles (4970 entrées) et un bruyant avec un son et quelques bruits en arrière-plan (environ 20000 entrées). Veuillez noter que chaque entrée de données comporte plusieurs étiquettes. Les deux ensembles de données ont été étiquetés. Le principal défi du concours (identifié par la grande majorité des participants) était d’utiliser correctement l’ensemble de données bruyantes pour améliorer la performance sur les données sélectionnées.
Nous avons été évalués en fonction d’une mesure personnalisée : la précision moyenne du classement des étiquettes pondérée par l’étiquette a également été abrégée. Pour donner une échelle, le 1 % le plus élevé a obtenu une note de 0,76, tandis qu’une médaille de bronze (environ 12 % le plus élevé) a obtenu une note de 0,695 ou plus. Mon score final lors de l’étape 1 était de 0,686, ce qui me place dans le top 15%.
Transformées de fourier rapides et melspectrogrammes : comment alimenter les sons en CNN ?
Depuis le début de l’article, vous pourriez trouver bizarre que je parle de la vision par ordinateur et des sons en même temps. En effet, un son est un signal temporel composé de multiples échantillons. Dans un premier temps, on pourrait penser qu’on peut alimenter un son dans un CNN en appliquant des convolutions 1D ou dans un modèle basé sur le LSTM. Cependant, les deux techniques n’ont pas donné de résultats convaincants, probablement en raison de la perte d’information subie par l’alimentation d’un signal brut dans un modèle. L’alimentation d’un signal brut entraîne une perte importante d’informations à savoir, fréquence, phase, amplitude. Après quelques expériences, les deux modèles n’ont pas donné un lwlrap supérieur à 0,5. Assez décevant…
En règle générale pour la classification audio, nous transformons les sons en une représentation 2D beaucoup plus complète (une image) que nous alimentons dans un CNN. Cette représentation peut être un MFCC, un Chroma, un CQT-Transform, mais c’est souvent un melspectrogramme.

Pour comprendre comment un melspectrogramme est généré, nous devons d’abord comprendre ce qu’une transformée de Fourier fait à notre signal. La transformée de Fourier rapide (un algorithme modifié avec une complexité o(nlogn) inférieure à la version originale o(n2)) convertit un signal sonore de son domaine temporel original en une représentation dans le domaine de fréquence.
Ensuite, nous appliquons une série de transformations pour finalement obtenir la représentation mel-spectogramme.
Pour effectuer cette série de calculs, vous pouvez directement utiliser la bibliothèque librosa qui a diverses fonctions pour effectuer l’analyse des fonctions audio.
Lectures supplémentaires :
Comment convertir des sons en images en Python (un noyau de Daisukelab) : https://www.kaggle.com/daisukelab/creating-fat2019-preprocessed-data
Un ensemble d’ordinateurs portables pour l’analyse des caractéristiques audio : https://musicinformationretrieval.com/
Une introduction à la bibliothèque librosa en Python : https://towardsdatascience.com/audio-classification-using-fastai-and-on-the-fly-frequency-transforms-4dbe1b540f89
Mixup : un must pour obtenir des résultats de pointe en vision par ordinateur
En termes simples, Mixup est une technique d’augmentation de données qui crée de nouvelles entrées de données à partir d’une relation linéaire entre deux entrées de données existantes. Nous pouvons le résumer avec cette formule. Γ sont des tenseurs qui représentent des images, tandis que λ sont des poids.

La même transformation est appliquée à la cible :

Il ne s’agit que d’une moyenne pondérée de deux échantillons de données existants. Par exemple, nous pourrions choisir λ = 0,7. Si Γ1 représente un chien et Γ2 un chat, Γnew représentera quelque chose entre un chien et un chat, plus proche du chien que le chat. Si vous regardez l’image associée à Γnew, il peut ne pas faire beaucoup de sens pour vous, mais pour l’ordinateur, il voit clairement un chien, augmentant ainsi l’ensemble de données d’image de chien.

Comme vous pouvez le voir, il peut agir comme une technique puissante d’augmentation des données en créant de nouvelles données à partir d’autres morceaux existants de données. Il est particulièrement utile lorsque vous devez faire face à un déséquilibre de classe. C’était le cas lors de cette compétition (où certaines étiquettes avaient très peu d’occurrences, alors que d’autres en avaient beaucoup plus). Cette technique unique m’a aidé à briser la barrière de 0,6 lwlrap, de 0,57 à 0,65 sur le classement (combiné avec d’autres techniques énumérées ci-dessous).
Lectures supplémentaires :
Document de recherche original de Mixup : https://arxiv.org/abs/1710.09412
Documentation Fast.ai sur Mixup : https://docs.fast.ai/callbacks.mixup.html
Augmentation du temps d’entraînement (ATE) : grattage des rangs dans le classement
L’augmentation du temps d’entraînement (ATE) est une forme de technique d’augmentation des données utilisée pendant l’inférence. Les résultats de ATE sont obtenus en calculant la moyenne pondérée des prédictions standard et des prédictions faites sur votre ensemble de données après l’application des techniques d’augmentation des données. Sans surprise, l’équation ressemble beaucoup à celle du Mixup :

Par défaut, dans fast.ai, le coefficient bêta est fixé à 0,4.
Notez que dans Fast.ai, ATE calcule les probabilités log (d’où les nombres négatifs). Pour passer des probabilités logarithmiques aux probabilités « standard » (entre 0 et 1), il suffit de calculer l’exponentielle des probabilités.
Le seul problème auquel vous pouvez faire face est le temps qu’il faut au modèle pour calculer les prévisions. Surtout si vous avez des contraintes de temps serrées pour l’exécution de votre modèle, ATE pourrait ne pas être un bon choix.
Quant à la compétition, elle m’a fait sauter (avec Mixup) de 0.57 au classement à 0.65.
Transfert, apprentissage semi-supervisé et pseudo-étiquetage
Le transfert d’apprentissage consiste à pré-former votre modèle avec un ensemble de données, puis à le former avec l’ensemble de données le plus proche de ce que vous voulez prédire. C’est une technique qui permet un entraînement plus rapide et une convergence plus stable à la perte optimale. C’est maintenant une norme dans l’industrie, que ce soit pour la vision par ordinateur ou NLP avec des modèles basés sur ULMFiT et BERT.
Pour ce concours, j’ai d’abord choisi de pré-former mon modèle sur l’ensemble de données bruyantes pour former mon modèle sur l’ensemble de données curated par la suite. Sur ma machine locale, mon lwlrap est passé de 0,81 à 0,83. Rappelons que la compétition ne permettait pas les modèles pré-formés.
La deuxième technique que j’ai essayée était l’apprentissage semi-supervisé. C’est particulièrement utile si vous avez beaucoup de données non étiquetées. Il aide le modèle à cartographier la distribution des données et permet une convergence plus rapide.
Vous feriez mieux de prendre une semaine pour étiqueter les données supplémentaires plutôt que d’essayer de créer un modèle qui tirerait parfaitement profit des données non étiquetées.
J’ai choisi un type particulier d’apprentissage semi-supervisé : le pseudo-étiquetage des données bruyantes. Dans ce concours, nous avions un grand nombre de données bruyantes. Plutôt que d’utiliser les étiquettes existantes, j’ai formé un modèle sur les données sélectionnées, puis j’ai utilisé ce modèle pour étiqueter mes données bruyantes. Finalement, en combinant les données organisées avec les données bruyantes nouvellement étiquetées, j’ai re-formé mon modèle. Bien que, il n’a pas amélioré de manière significative la performance en raison de la trop grande différence entre la distribution de données organisée et celle bruyante, dans un modèle d’ensemble, la performance a augmenté.
Je peux conclure en disant qu’il vaut mieux prendre une semaine pour étiqueter les données supplémentaires plutôt que d’essayer de créer un modèle qui tirerait parfaitement profit des données non étiquetées. Les techniques d’apprentissage semi-supervisées sont généralement adaptées lorsque vous avez une grande quantité de données de rechange.
Lecture supplémentaire :
Une explication complète du pseudo-étiquetage : https://www.analyticsvidhya.com/blog/2017/09/pseudo-labelling-semi-supervised-learning-technique/
Validation croisée K-Fold et agrégation bootstrap : obtenir des résultats plus stables pendant l’inférence
Comme le CV K-Fold n’est pas particulièrement mis en avant dans le cours fast.ai, je ne l’ai pas vraiment utilisé bien que ce soit un standard dans l’industrie. Permettez-moi de rappeler rapidement la définition de la validation K-Fold : c’est une technique par laquelle un jeu de données est divisé en K-Fold, un modèle est formé sur les plis K-1 et validé sur le pli restant. Évidemment, les modèles K sont générés puisque chaque modèle a un ensemble de validation différent, ce qui permet une évaluation plus précise et plus uniforme du rendement.

Mais au-delà d’être une technique de validation, K-Fold CV peut être utilisé dans un modèle d’ensemble (le mot fantaisie pour cela est l’agrégation bootstrap). Ce mot cache des techniques assez simples et simples où par exemple vous calculez la moyenne de toutes les prédictions sur vos plis K. Cette technique d’ensemble donne habituellement de meilleurs résultats puisque la variance du modèle global est considérablement réduite.
Technique d’assemblage : la clé pour entrer dans le top 5%
Mon paragraphe précédent introduisait une notion clé de la science des données concurrentielles et, de façon générale, de la création de modèles plus précis : le concept d'assemblage. En termes simples, assembler est une technique où plusieurs modèles sont mis ensemble pour gagner la stabilité dans vos prévisions et la précision. Pour obtenir un modèle d’ensemble hautement performant, vous devez vérifier la corrélation entre tous vos modèles. Moins il y a de corrélation, mieux c’est. Pour ce faire, vous calculez le coefficient de corrélation de Pearson :

Lorsque σ est l’écart-type de la série statistique, cov(X,Y) est la covariance des séries statistiques X et Y.
En combinant un modèle de base simple avec uniquement des données organisées, un modèle d’apprentissage de transfert et un modèle de pseudo-étiquetage, j’ai pu atteindre mon score le plus élevé au classement : 0,686.
Pour plus de clarté, les séries statistiques X et Y sont les prédictions de vos modèles. Pour chaque modèle que vous créez, vous pouvez calculer le coefficient de corrélation de Pearson entre les deux, et jeter les modèles qui sont fortement corrélés.
Dans ce concours, X et Y seraient des matrices contenant les probabilités d’appartenir à l’une des 80 classes pour chaque échantillon de données.
Quant à la compétition, la technique de ensemblage m’a clairement donné l’occasion de m’approcher d’une médaille de bronze. En combinant un modèle de base simple avec uniquement des données organisées, un modèle d’apprentissage de transfert et un modèle de pseudo-étiquetage, j’ai pu atteindre mon score le plus élevé au classement : 0,686.
Lecture supplémentaire :
Un guide complet pour la technique d'assemblage, de moyenne à la généralisation empilée : https://mlwave.com/kaggle-ensembling-guide/
À partir de là, où allons-nous ?
Il est maintenant temps d’adopter un point de vue critique sur ma performance. Comme je n’ai pas gagné de médaille, il y a beaucoup de choses que j’aurais pu améliorer. Je vais me forcer à penser à des choses que j’aurais pu faire différemment, ou en plus de ce que j’ai déjà fait.
Connaissez vos données
Probablement mon erreur la plus critique a consisté à se précipiter trop vite pour construire un modèle, au lieu d’essayer d’abord de comprendre la distribution des données et le type de bruit dans l’ensemble de données bruyantes. Cela m’aurait permis de mieux comprendre la difficulté de prévoir une étiquette et de lire des documents de recherche plus pertinents pour enlever ou atténuer le bruit sur les pistes.
Lire des documents de recherche
Celui-ci est plus un rappel qu’une vraie critique. J’ai découvert comment la lecture de documents de recherche capitale était d’appliquer des techniques qui mènent à des résultats de pointe. Avec la démocratisation de l’IA grâce au MOOC comme le cours fast.ai (merci encore à Jeremy Howard, Rachel Thomas et la fantastique équipe derrière le projet), de plus en plus de personnes ont accès à de puissants outils d’apprentissage automatique qui les rapprochent des résultats les plus récents. Lire des articles de recherche et être en mesure de mettre en œuvre certaines techniques décrites est un avantage inestimable car il vous différencie de la concurrence. Peu de gens sont prêts à prendre le temps de le lire et encore moins à mettre en œuvre une technique.
L’un des principaux objectifs que je me suis fixés est d’être suffisamment à l’aise avec Fast.ai et son framework sous-jacent PyTorch pour implémenter et intégrer mes propres extraits de code à la bibliothèque. Par exemple, je suis tombé sur ce document de recherche https://arxiv.org/abs/1905.02249 qui semble être assez efficace puisqu’il est dit que MixMatch peut réduire d’un facteur de 4 le taux d’erreur. Cependant, après plusieurs tentatives, je ne suis pas encore en mesure de le mettre en œuvre.
Utiliser plus de canaux de données ?
Nous avons déjà parlé des melspectogrammes et de la façon dont ils ont été créés. Mais d’autres représentations audio peuvent être créées à savoir, Chroma, Mel Frequency Cepstral Coefficients (MFCC), Constant-Q Transform pour n’en nommer que quelques-unes. Toutes ces représentations mettent l’accent sur différents aspects d’un signal audio : on peut explorer l’amplitude tandis que l’autre la phase ou la fréquence. Je n’ai pas été en mesure de construire un modèle suffisamment précis pour tirer des leçons de la phase, par exemple. Je crois fermement que c’était un élément clé de la concurrence puisqu’il ajoute plus d’informations aux modèles mel-spectogram.
Techniques de cumul plus complexes : moyenne pondérée, généralisation empilée ?
Tout en utilisant une technique d’ensemble, je n’ai pas combiné mes modèles d’une manière complexe. J’ai simplement calculé la moyenne de toutes mes prédictions. J’aurais pu essayer de peaufiner mon modèle en choisissant des poids adéquats, créant ainsi une moyenne pondérée pour mes prédictions.
J’aurais même pu essayer d’utiliser un réseau neuronal qui prend comme entrée toutes les prédictions de mes différents modèles et qui essaie de détecter des modèles non linéaires entre les différentes prédictions. L’un des défis était la limitation des données. Nous n’avions que 4970 échantillons de données dans l’ensemble de données curated, et enlever 1000 échantillons de données aurait été contre-productif, puisque 4970 était déjà un nombre faible.
Je n’ai pas essayé de former mon modèle sur le jeu de données bruyant, puisque la distribution était trop loin des testset.
Conclusion
Je vais être bref pour la conclusion, puisque l’article est déjà assez long (félicitations et merci si vous êtes encore là). La leçon la plus critique que je tire de cette compétition est que la construction de modèles robustes est un processus empirique. Vous essayez, vous échouez, vous pensez, et vous corrigez. Vous devez essayer beaucoup de choses pour devenir bon. La compétition aide à développer une intuition pour ce qui pourrait fonctionner et ce qui pourrait ne pas fonctionner.
J’espère que vous avez aimé cet article. Encore une fois, n’hésitez pas à me corriger si je me trompe sur certains points ou à partager vos réflexions sur la concurrence dans la section des commentaires.
Et consultez mon autre article de blog : https://medium.com/@PABTennnis/how-to-create-a-neural-network-from-scratch-in-python-math-code-fd874168e955
Kaggle : https://www.kaggle.com/rftexas

Commentaires