
Uno sguardo alla scienza dei dati competitiva : le migliori pratiche per la visione computerizzata
- Literature & Cie

- 18 janv. 2021
- 10 min de lecture
Come diverse tecniche possono migliorare notevolmente le prestazioni dei vostri modelli di visione del computer…
Introduzione
Dal momento che il concorso Freesound Audio Tagging 2019 sta per concludersi, ho deciso di scrivere un articolo sulle migliori pratiche e tecniche per costruire un modello di computer vision robusto, che ho imparato durante il mio primo concorso di ricerca. Inoltre, è un modo per me di mettere le mie idee su carta per avere una panoramica strutturata e chiara delle tecniche che ho usato: quelle che hanno funzionato bene, così come quelle che non hanno prodotto un miglioramento significativo nel mio punteggio di test.
Come studente del corso Fast.ai, sono ancora all'inizio del mio percorso di apprendimento, quindi alcune osservazioni o tecniche che potrebbero sembrare ovvie per i più esperti di voi.
Come sempre, vi incoraggio fortemente a correggermi, a chiedermi precisazioni su un punto specifico se non lo capite o se non è chiaro, e ad aggiungere alcune osservazioni nella sezione dei commenti !
La lezione più critica che ricevo da questa competizione è che costruire modelli robusti è un processo empirico. Competere aiuta a sviluppare un'intuizione per ciò che potrebbe funzionare o meno.
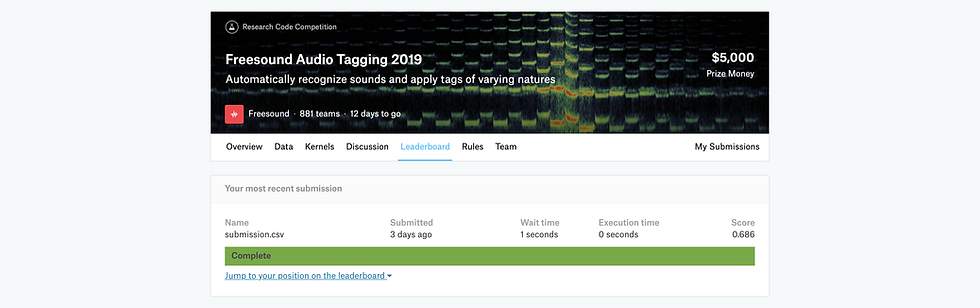
Per darvi un po' di contesto, il concorso è di tagging (classificazione) suoni (gatto, cascate, strumenti musicali...). Ci sono stati dati due set di dati : uno curato con suoni chiaramente udibili (4970 voci) e uno rumoroso con un suono e alcuni rumori in background (20000 voci dispari). Si noti che ogni immissione di dati ha più etichette. Entrambi i set di dati sono stati etichettati. La sfida principale del concorso (identificata dalla stragrande maggioranza dei partecipanti) è stato quello di utilizzare correttamente il set di dati rumorosi per migliorare le prestazioni sui dati curati.
Siamo stati valutati rispetto ad una metrica personalizzata: l'etichetta ponderata classifica la precisione media anche abbreviata lwlrap. Per dare una scala, il top 1% ha ottenuto un punteggio lwlrap di 0,76, mentre una medaglia di bronzo (top 12% circa) è stato premiato con un punteggio di 0,695 o superiore. Il mio punteggio finale durante la fase 1 era 0.686, che mi ha messo nella top 15%.
Fast Fourier Trasforma e melspectrograms : come alimentare i suoni in una CNN ?
Dall'inizio dell'articolo, si potrebbe trovare strano che parlo di visione al computer e suoni allo stesso tempo. Infatti, un suono è un segnale basato sul tempo composto da più campioni. In un primo momento, potremmo pensare di poter alimentare un suono in una CNN applicando convoluzioni 1D o in un modello basato su LSTM.
Tuttavia, entrambe le tecniche non hanno dato risultati convincenti, probabilmente a causa della perdita di informazioni derivante dall'immissione di un segnale grezzo in un modello. L'alimentazione di un segnale grezzo porta ad una significativa perdita di informazioni e cioè frequenza, fase, ampiezza. Dopo alcuni esperimenti, entrambi i modelli non hanno dato un lwlrap oltre 0,5. Abbastanza deludente…
Come regola generale per la classificazione audio, di solito trasformiamo i suoni in una rappresentazione 2D molto più completa (un'immagine) che alimentiamo in una CNN. Questa rappresentazione può essere un MFCC, un Chroma, una CQT-Transform, ma spesso è uno spettrogramma di mel.

Per capire come viene generato uno spettrogramma di mel, dobbiamo prima capire cosa fa una trasformata di Fourier al nostro segnale. La Trasformata di Fourier veloce (un algoritmo modificato con una complessità o(nlogn) inferiore alla versione originale o(n2)) converte un segnale sonoro dal suo dominio di tempo originale ad una rappresentazione nel dominio di frequenza.
Poi applichiamo una serie di trasformazioni per ottenere finalmente la rappresentazione mel-spectogram.
Per eseguire questa serie di calcoli, è possibile utilizzare direttamente la libreria librosa che ha varie funzioni per eseguire l'analisi delle funzionalità audio.
Letture aggiuntive :
Come convertire i suoni in immagini in Python (un kernel di Daisukelab): https://www.kaggle.com/daisukelab/creating-fat2019-preprocessd-data
Un set di notebook per l'analisi delle caratteristiche audio : https://musicinformationretrieval.com/
Un’introduzione alla libreria librosa in Python : https://towardsdatascience.com/audio-classification-using-fastai-and-on-the-fly-frequency-transforms-4dbe1b540f89
Mixup : un must per ottenere risultati all'avanguardia nella visione computerizzata
In poche parole, Mixup è una tecnica di aumento dei dati che crea nuove voci di dati da una relazione lineare tra due voci di dati esistenti. Possiamo riassumerlo con questa formula. Γ sono tensori che rappresentano le immagini, mentre λ sono pesi.

La stessa trasformazione si applica al target :

Non è altro che una media ponderata di campioni di dati due esistenti. Ad esempio, potremmo scegliere λ = 0,7. Se Γ1 rappresenta un cane e Γ2 un gatto, Γnew rappresenterà qualcosa tra un cane e un gatto, più vicino dal cane che dal gatto. Se si guarda l'immagine associata a Γnew, non può avere molto senso per voi, ma per il computer vede chiaramente un cane, quindi aumentare l'immagine del cane dataset.

Come potete vedere può agire come una potente tecnica di aumento dei dati creando nuovi dati da altri pezzi di dati esistenti. È particolarmente utile quando si ha a che fare con lo squilibrio di classe. Era il caso durante questo concorso (dove alcune etichette hanno avuto pochissimi eventi, mentre altre hanno avuto molto di più). Questa singola tecnica mi ha aiutato a superare la barriera 0.6 lwlrap, da 0.57 a 0.65 in classifica (in combinazione con altre tecniche elencate di seguito).
Letture aggiuntive :
Documento di ricerca originale Mixup: https://arxiv.org/abs/1710.09412
Documentazione Fast.ai su Mixup : https://docs.fast.ai/callbacks.mixup.html
Training Time Augmentation (TTA) : raschiare gradi nella classifica
Training Time Augmentation (TTA) è una forma di tecnica di aumento dei dati utilizzata durante l'inferenza. I risultati di TTA sono ottenuti calcolando la media ponderata delle previsioni standard e delle previsioni fatte sul vostro insieme di dati dopo l'applicazione delle tecniche di aumento di dati. Non sorprende che l'equazione sia molto simile a quella di Mixup :

Per impostazione predefinita, in fast.ai il coefficiente beta è fissato a 0.4.
Si noti che in Fast.ai, TTA calcola log-probabilità (quindi i numeri negativi). Per passare da probabilità log a probabilità "standard" (tra 0 e 1), basta calcolare l'esponenziale delle probabilità.
L'unico problema che si può affrontare è quanto tempo il modello impiega per calcolare le previsioni. Soprattutto se si dispone di vincoli di tempo stretti per l'esecuzione del modello, TTA potrebbe non essere una buona scelta.
Per quanto riguarda la competizione, mi ha fatto saltare (con Mixup) da 0.57 in classifica a 0.65.
Trasferimento, apprendimento semi-supervisionato e pseudo etichettatura
Transfer learning consiste nel pre-formazione del modello con un set di dati e poi la formazione con il set di dati che è il più vicino a quello che si desidera prevedere. Si tratta di una tecnica che permette un allenamento più veloce e una convergenza costante alla perdita ottimale. Ora è uno standard nel settore, che si tratti di computer vision o NLP con modelli basati su Ulmfit e BERT.
Per questo concorso, ho scelto di pre-formare il mio modello sul set di dati rumoroso per addestrare il mio modello sul set di dati curato alla fine. Sulla mia macchina locale, il mio lwlrap saltato da 0,81 a 0,83. Ricordiamo che la concorrenza non ha permesso modelli pre-addestrati.
La seconda tecnica che ho provato era apprendimento semi-supervisionato. È particolarmente utile se si dispone di un sacco di dati senza etichetta. Aiuta il modello a mappare la distribuzione dei dati e permette una convergenza più veloce.
È meglio prendere una settimana per etichettare i dati aggiuntivi piuttosto che cercare di creare un modello che sfrutta perfettamente i dati non marcati.
Ho scelto un particolare tipo di apprendimento semi-supervisionato : pseudo-etichettatura dei dati rumorosi. In questa competizione, abbiamo avuto un gran numero di dati rumorosi. Piuttosto che usare le etichette esistenti, ho formato un modello su dati curati, poi ho usato questo modello per etichettare i miei dati rumorosi. Infine, combinando i dati curati con i dati rumorosi appena etichettati, ho ri-addestrato il mio modello. Anche se non migliorò significativamente la performance a causa di un'eccessiva differenza tra la distribuzione dei dati curata e quella rumorosa, in un modello di ensemble la performance aumentò.
Posso concludere affermando che è meglio impiegare una settimana per etichettare i dati aggiuntivi piuttosto che cercare di creare un modello che sfrutti perfettamente i dati non etichettati. Le tecniche di apprendimento semi-supervisionate sono in genere adatte quando si dispone di una grande quantità di dati di ricambio.
Lettura aggiuntiva :
Una spiegazione completa della pseudo etichettatura : https://www.analyticsvidhya.com/blog/2017/09/pseudo-labelling-semi-supervised-learning-technique/
K-Fold Cross Validation e bootstrap aggregating : ottenere risultati più stabili durante l’inferenza
Poiché K-Fold CV non è particolarmente evidenziato nel corso fast.ai, Non ho davvero usato anche se è uno standard nel settore. Permettetemi di ricordare rapidamente la definizione di validazione K-Fold : è una tecnica in cui un dataset è diviso in K-Fold, un modello è addestrato su pieghe K-1 e validato sulla piega rimanente. Ovviamente, i modelli K sono generati poiché ogni modello ha un set di validazione diverso. Questo porta a una valutazione delle prestazioni più accurata e coerente.

Ma oltre ad essere una tecnica di convalida, K-Fold CV può essere utilizzato all'interno di un modello di ensemble (la parola di fantasia per questo è l'aggregazione bootstrap). Questa parola nasconde tecniche abbastanza semplici e semplici in cui, per esempio, si calcola la media di tutte le previsioni sul tuo K pieghe. Questa tecnica di ensemble di solito produce migliori prestazioni in quanto la varianza del modello complessivo è drasticamente ridotta.
Tecnica di montaggio : la chiave per entrare nella top 5
Il mio paragrafo precedente ha introdotto una nozione chiave per la scienza dei dati competitiva e, in generale, per la creazione di modelli più accurati : il concetto di Ensembling. In poche parole, Nsembling è una tecnica in cui diversi modelli sono messi insieme per ottenere stabilità nelle previsioni e precisione.
Per ottenere un modello di ensemble altamente performante, è necessario verificare la correlazione tra tutti i modelli. Meno correlato, meglio è. Per farlo, si calcola il coefficiente di correlazione di Pearson :

Dove σ è la deviazione standard delle serie statistiche, cov(X,Y) la covarianza delle serie statistiche X e Y.
Combinando un semplice modello di base con solo dati curati, un modello di apprendimento di trasferimento e un modello di pseudo-etichettatura, sono stato in grado di raggiungere il mio punteggio più alto nella classifica : 0.686.
Per essere più chiari, le serie statistiche X e Y sono le previsioni dei vostri modelli. Per ogni modello che si crea, è possibile calcolare il coefficiente di correlazione di Pearson tra di loro, e scartare i modelli che sono altamente correlati.
In questa competizione, X e Y sarebbero matrici che contengono le probabilità di appartenere ad una delle 80 classi per ogni campione di dati.
Per quanto riguarda la competizione, la tecnica di montaggio mi ha dato chiaramente l'opportunità di avvicinarmi a una medaglia di bronzo. Combinando un semplice modello di base con solo dati curati, un modello di apprendimento di trasferimento e un modello di pseudo-etichettatura, sono stato in grado di raggiungere il mio punteggio più alto nella classifica : 0.686.
Lettura aggiuntiva :
Una guida completa per la tecnica di assemblaggio, dalla media alla generalizzazione stacked : https://mlwave.com/kaggle-ensembling-guide/
Dove andare da qui ?
È ora di adottare un punto di vista critico sulla mia performance. Dal momento che non ho guadagnato una medaglia, ci sono un sacco di cose che avrei potuto migliorare. Mi costringerò a pensare a cose che avrei potuto fare diversamente, o in aggiunta a ciò che ho già fatto.
Conoscere i tuoi dati
Probabilmente il mio errore più critico consisteva nel correre troppo veloce per costruire un modello, invece di cercare prima di capire la distribuzione dei dati e il tipo di rumore nel set di dati rumorosi. Mi avrebbe permesso di capire meglio la difficoltà di prevedere un'etichetta e di leggere documenti di ricerca più pertinenti per rimuovere o attenuare il rumore sui binari.
Leggere articoli di ricerca
Questo è più un promemoria che un vero critico. Ho scoperto come la lettura del capitale documenti di ricerca è stato quello di applicare tecniche che portano a state-of-the-art risultati. Con la democratizzazione dell'IA grazie a MOOC come corso fast.ai (grazie ancora Jeremy Howard, Rachel Thomas e il fantastico team dietro il progetto), sempre più persone hanno accesso a potenti strumenti di apprendimento automatico che li avvicinano ai risultati di ultima generazione. Leggere documenti di ricerca e di essere in grado di implementare alcune tecniche descritte è un vantaggio inestimabile in quanto si differenzia dalla concorrenza. Poche persone sono disposte a prendersi il tempo di leggerlo e ancora meno per implementare una tecnica.
Uno degli obiettivi principali che ho impostato per me è quello di essere abbastanza confortevole con Fast.ai e la sua struttura sottostante Pytorch per implementare e integrare i miei frammenti di codice alla libreria. Per esempio, mi sono imbattuto in questo documento di ricerca https://arxiv.org/abs/1905.02249. che sembra essere abbastanza efficiente in quanto si afferma che Mixmatch può ridurre di un fattore 4 il tasso di errore. Tuttavia, dopo diversi tentativi, non sono ancora in grado di implementarlo.
Usare più canali di dati ?
Abbiamo già parlato di mel-spectograms e di come sono stati creati. Ma si possono creare altre rappresentazioni audio: Chroma, Mel Frequency Cepstral Coefficients (MFCC), Constant-Q Transform per citarne solo alcuni. Tutte queste rappresentazioni enfatizzano diversi aspetti di un segnale audio : uno potrebbe esplorare l'ampiezza mentre l'altro la fase o la frequenza. Non ero in grado di costruire un modello abbastanza preciso che avrebbe imparato dalla fase, per esempio. Sono fermamente convinto che sia stata una chiave della competizione poiché aggiunge più informazioni ai modelli mel-spectogram.
Tecniche di montaggio più complesse: media ponderata, generalizzazione impilata ?
Pur usando una tecnica di insieme, non ho combinato i miei modelli in modo complesso. Ho semplicemente calcolato il mezzo di tutte le mie previsioni. Avrei potuto provare a perfezionare il mio modello scegliendo pesi adeguati, creando così una media ponderata per le mie previsioni.
Avrei anche potuto provare a usare una rete neurale che prende come input tutte le previsioni dai miei diversi modelli e che cerca di rilevare schemi non lineari tra le diverse previsioni. Una sfida era la limitazione dei dati. Avevamo solo 4970 campioni di dati nel set di dati curato, e la rimozione di 1000 campioni di dati sarebbe stato controproducente, dal momento che 4970 era già un numero basso.
Non ho provato ad addestrare il mio modello sul set di dati rumoroso, dal momento che la distribuzione era troppo lontana da quella del testset.
Conclusione
Sarò breve per la conclusione, dal momento che l'articolo è già abbastanza lungo (congratulazioni e grazie se siete ancora qui). La lezione più critica che ricevo da questa competizione è che costruire modelli robusti è un processo empirico. Ci provi, fallisci, pensi, e correggi. Devi provare un sacco di cose per diventare bravo. Competere aiuta a sviluppare un'intuizione per ciò che potrebbe funzionare e ciò che non potrebbe.
Spero ti sia piaciuto questo articolo. Anche in questo caso, non esitate a correggermi se mi sbaglio su alcuni punti o per condividere i vostri pensieri sulla concorrenza nella sezione commenti.
E controllare il mio altro post sul blog : https://medium.com/@PABTennnis/how-to-create-a-neural-network-from-scratch-in-python-math-code-fd874168e955
Kaggle: https://www.kaggle.com/rftexas
Fonte (articolo di origine) : https://towardsdatascience.com/a-glance-into-competitive-data-science-the-best-practices-for-computer-vision-2c77c5d98d19

Commentaires